
Eine Exportaufgabe ermöglicht es Ihnen, Selligent by Zeta-Daten zu einem externen Ort zu exportieren. Sie können definieren, wann und wie oft der Export ausgeführt werden muss und ob jemand über den Status der Exportaufgabe benachrichtigt werden muss. Darüber hinaus müssen Sie aus einer Reihe von Exportorten für das Speichern der Daten auswählen.
Eine Exportaufgabe kann auf zwei Arten erstellt werden:
- Vom Flyout-Menü aus, das vom Eintrag "Data Exchange" in der linken Navigationsleiste aus verfügbar ist. Klicken Sie auf die Schaltfläche Neu und wählen Sie die Art der Aufgabe aus der Dropdown-Liste aus.
- Wählen Sie im Start Seite Neu > Exportaufgabe aus. Ein Assistent führt Sie durch den Erstellungs- und Konfigurationsvorgang.

HINWEIS: Die übersicht der Schritte kann verwendet werden, um beim Bearbeiten einer Aufgabe direkt zu einem spezifischen Schritt zu gehen.
- Allgemeine Eigenschaften festlegen
- Datenquelle definieren, die für den Export verwendet wird
- Optional — Trigger-Datei festlegen
- Optional — Verschlüsseln und zippen
- Ziel für die Exportdatei definieren
- Verlauf anzeigen
Allgemeine Eigenschaften festlegen
Eigenschaften
- Ordnerpfad — Hierbei handelt es sich um den Ort in der Ordnerstruktur, an dem die Aufgabe gespeichert ist.
- Name und Beschreibung — Diese sollten möglichst eindeutig sein, damit die Aufgabe auf der Startseite leicht erkannt werden kann.
- Komponenten-Label – Das (die) dieser Komponente zugewiesene(n) Label(s). Wählen Sie ein oder mehrere Labels aus der Dropdown-Liste. (Diese Labels werden in der Admin-Konfiguration konfiguriert). Benutzer mit der entsprechenden Zugriffsberechtigung können hier auch neue Labels erstellen, indem sie den neuen Label-Wert in das Feld eingeben.
- API-Name — Dieser Name wird verwendet, wenn die Aufgabe über die API ausgeführt wird. Standardmäßig wird der API-Name mit dem Namen vervollständigt, der der Aufgabe gegeben wurde.
Plan
Der Zeitplanschalter gibt an, ob diese Aufgabe ihre eigene Zeitplanung haben soll. Das ist nicht notwendig, wenn diese Aufgabe Teil einer Batch-Ausführung von Aufgaben (Batch-Job) ist - in diesem Fall erbt sie die Zeitplanung des übergeordneten Batch-Jobs.
Im Abschnitt "Plan" werden die Gültigkeitsdauer für die Aufgabe sowie das Erfolgen der Ausführung definiert.
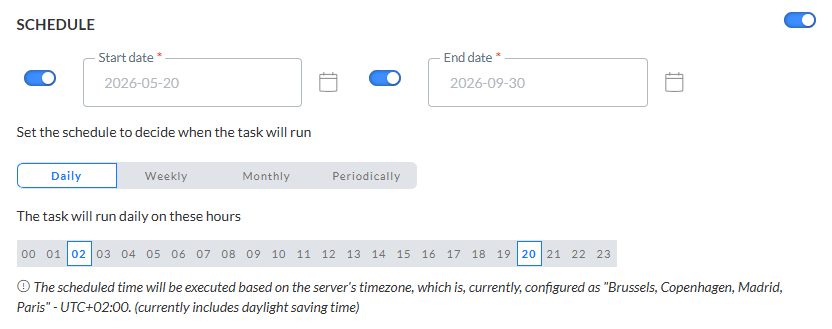
Start- und Enddatum — Sie können ein Startdatum und/oder Enddatum für die Aufgabe einstellen. Zum Beispiel kann Ihre Aufgabe jetzt starten, muss aber unendlich laufen.
Häufigkeit — Geben Sie an, wann die Aufgabe ausgeführt werden soll:
- Täglich — Wählen Sie die Stunden des Tages aus, in denen die Aufgabe ausgeführt werden soll. Sie können mehr als eine ausführen.
- Wöchentlich — Wählen Sie die Tage der Woche aus, an denen die Aufgabe ausgeführt werden soll. Die Aufgabe kann mehr als einmal die Woche ausgeführt werden. Sie können auch die Startzeit festlegen.
- Monatlich — Wählen Sie die Tage des Monats aus, an denen die Aufgabe ausgeführt werden soll. Sie können auch die Tageszeit auswählen, zu der die Aufgabe starten soll.
- Periodisch — Legen Sie das erneute Erfolgen der Aufgabe, in Minuten ausgedrückt, fest. Die Aufgabe wird zum Beispiel alle 10 Minuten ausgeführt.
Hinweis: Die geplante Zeit wird auf Basis der Zeitzone des Servers ausgeführt. Die zurzeit konfigurierte Zeitzone des Servers wird neben dem Info-Symbol angezeigt.
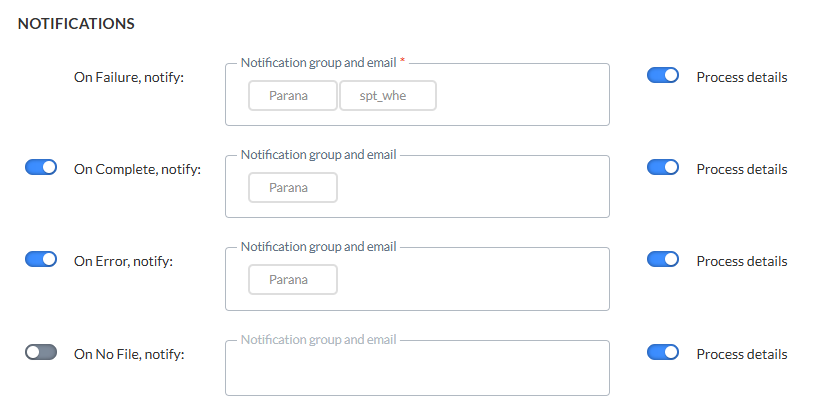
Benachrichtigungen
Es kann auch eine Nachricht gesendet werden
- * OnFailure — Bei Fehlschlagen des Prozesses Es ist mindestens eine Benachrichtigungsgruppe / E-Mail-Adresse erforderlich.
- OnComplete — Bei erfolgreichem Abschluss der Aufgabe
- OnError — Mit Fehlern abgeschlossen (Auftrag wurde abgeschlossen, aber eine oder mehrere Aufgaben führte/n zu Fehlern/Ausnahmen)
- OnNoFile — Wenn keine Datei gefunden werden konnte
Die Details des Vorgangs können in die Nachricht einbezogen werden. Außerdem wird die Instanz, bei der das Problem aufgetreten ist, in den Betreff der Nachricht einbezogen.
Um die Option zu aktivieren, markieren Sie einfach das Kontrollkästchen und geben Sie eine oder mehrere E-Mail-Adressen ein. (Mehrere E-Mail-Adressen werden durch ein Semikolon getrennt.) Sie können auch eine Benachrichtigungsgruppe auswählen. Diese Benachrichtigungsgruppen werden in der Admin-Konfiguration erstellt.
Hinweis: Benachrichtigungs-E-Mails für das Fehlschlagen der Aufgabe sind obligatorisch. Andere Benachrichtigungen sind optional.
Klicken Sie, wenn Sie fertig sind, auf Weiter.
Terminplaner einstellen (Optional)
Hinweis: Der Terminplaner-Abschnitt ist nur sichtbar, wenn Terminplaner für Ihre Umgebung konfiguriert sind. Standardmäßig gibt es 1 Terminplaner. In diesem Fall wird dieser Abschnitt nicht angezeigt, da dieser Standard-Terminplaner verwendet wird. Wenn mehr als 1 Terminplaner konfiguriert ist, haben Sie Zugriff auf den Terminplaner-Abschnitt.
Wenn mehrere Aufgaben, Importe oder Exporte laufen, kann es eine gute Idee sein, einen unterschiedlichen Terminplaner zu verwenden, um sicherzustellen, dass lang laufende Aufgaben kleinere Aufgaben nicht stören. Das Auswählen eines Terminplaners ist optional, und wenn Sie den voreingestellten behalten, werden alle Aufgaben/Exporte/Importe trotzdem ausgeführt, aber wenn es eine größere Aufgabe gibt, wird die kleinere nur ausgeführt, wenn die größere beendet ist.

Sie können zwischen 3 verschiedenen Terminplanern auswählen: dem voreingestellten, dem benutzerdefinierten Terminplaner 1 und dem benutzerdefinierten Terminplaner 2. Wenn Sie verschiedene Terminplaner für Ihre Aufgaben auswählen, werden sie parallel ausgeführt, ohne einander zu stören. Wenn Sie also länger laufende Aufgaben haben, kann es eine gute Idee sein, diese mit einem anderen Terminplaner auszuführen.
Datenquelle definieren
Im Abschnitt "Datenquelle" können Sie definieren, welche Daten exportiert werden müssen.
Datenquelle
In diesem Abschnitt wählen Sie das gespeicherte Verfahren aus, das zum Abrufen der Daten aus der Datenbank verwendet wird.

Klicken Sie auf das Stiftsymbol, um auf den folgenden Dialog zuzugreifen:
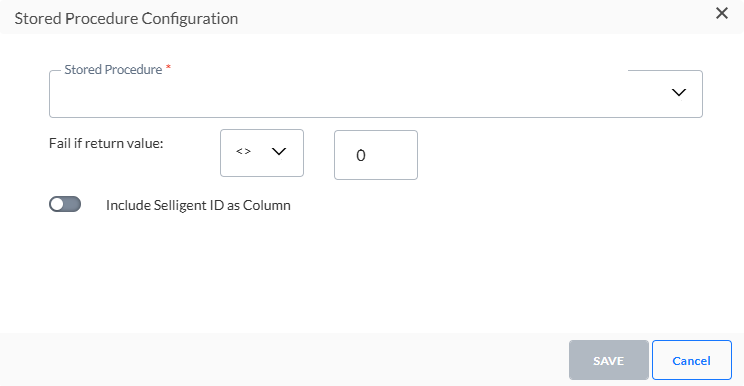
1. Wählen Sie das gespeicherte Verfahren aus der Dropdown-Liste aus. Wenn das gespeicherte Verfahren Parameter erfordert, werden zusätzliche Felder hinzugefügt, um die Werte für diese Parameter zu definieren.
2. Legen Sie als Nächstes das Fail-Constraint fest. Verwenden Sie den zurückgegebenen Wert des gespeicherten Verfahrens, um zu definieren, ob es fehlgeschlagen ist oder nicht.
-
Wenn im Entwurf des Stored Procedure kein expliziter Rückgabewert definiert ist, wird im Erfolgsfall der Wert 0 standardmäßig zurückgegeben. Andere Werte implizieren einen Fehler.
In diesem Fall stellen Sie das Fail-Constraint wie folgt ein: Fehler, wenn Rückgabewert <> 0.
-
Wenn der Entwurf für das Stored Procedure ein oder mehrere benutzerdefinierte Rückgabewerte enthält, hängen die Werte, die bei Erfolg oder Fehler zurückgegeben werden, von diesem Entwurf ab.
In diesem Fall entscheiden Sie, was Sie als Fail-Constraint betrachten.Beispiel 1:
Das Stored Procedure, das verwendet wird, definiert, dass der Wert 10 nach Ausführung bestimmter SQL-Anweisungen zurückgegeben wird und der Wert 12 nach Ausführung eines anderen Satzes von SQL-Anweisungen zurückgegeben wird.
Sie betrachten den Teil, der den Rückgabewert als 12 definiert, als einzigen erfolgreichen Teil. In anderen Fällen sollte er als Fehler betrachtet werden.
In diesem Fall stellen Sie das Fail-Constraint wie folgt ein: Fehler, wenn Rückgabewert <> 12.Beispiel 2:
Das verwendete Stored Procedure definiert die Rückgabewerte 1, 10, 50, 51, 52, 53, 54, 55, 56, 60.
Sie betrachten die Rückgabewerte 1, 10 und 50 als „erfolgreiche“ Werte. Die anderen geben an, dass etwas falsch ist, und werden daher als Fehler betrachtet.
In diesem Fall können Sie das Fail-Constraint wie folgt einstellen: Fehler, wenn Rückgabewert >= 51.
3. Wenn das gespeicherte Verfahren Parameter erfordert, geben Sie die Werte für die Parameter an. Parameter können vom Typ INPUT oder OUTPUT sein. Der Wert eines OUTPUT-Parameters kann als eine Variable festgelegt werden und diese Variable kann als INPUT-Parameter in einem anderen gespeicherten Verfahren verwendet werden.
4. Sie können die Selligent by Zeta-ID als Spalte in der Exportdatei einbeziehen. Diese ID ist eine Kombination des Zielgruppenlisten-ID und Kontakt-ID. Wenn Sie dies möchten, schalten Sie die Option ein.
Speichern Sie die Einstellungen für die Datenquelle. Sie müssen dies tun, bevor Sie zu den folgenden Konfigurationsoptionen gehen können.
Datei
In diesem Abschnitt definieren Sie die erzeugte Datei und ihre Eigenschaften.
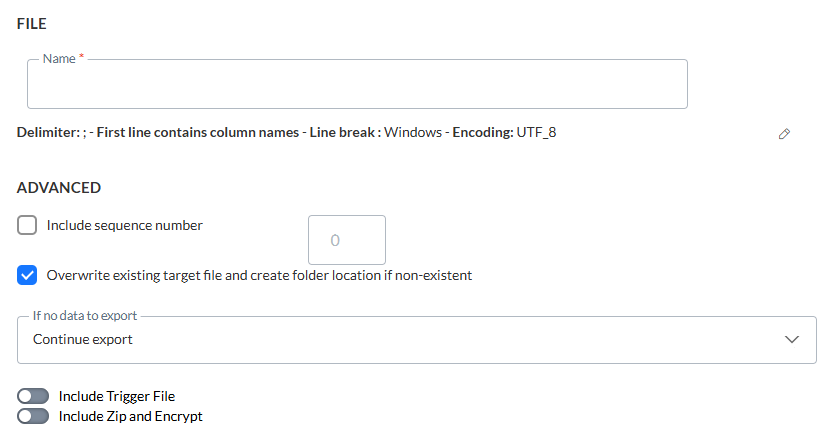
1. Definieren Sie den Namen der Exportdatei, die aus dem gespeicherten Verfahren erzeugt wurde.
Hinweis: Dieser Dateiname kann Ausdrücke enthalten. Sie können auf diese Ausdrücke über den Dialog Personalisierung zugreifen: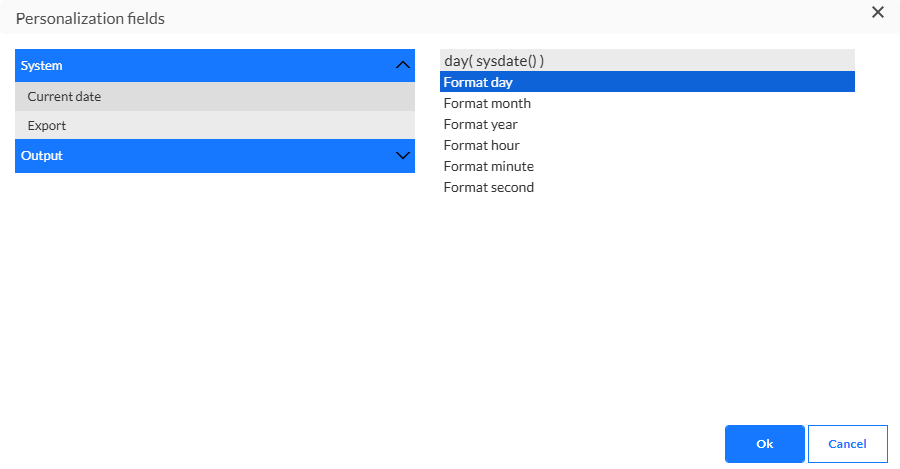
Exportdateinamen können mit den folgenden Ausdrücken personalisiert werden:
Für das aktuelle Datum:
* [%year(sysdate())%]
* [%month(sysdate())%]
* [%day(sysdate())%]
* [%hour(sysdate())%]
* [%minute(sysdate())%]
* [%second(sysdate())%]
Für mit dem Export verbundene Ausdrücke:
* [%export('sequenceNumber')%]
* [%export('rowCount')%]
* [%export('md5')%]
Für exportbezogene Ausdrücke:
* [%componentValue('OutputParameterName')%]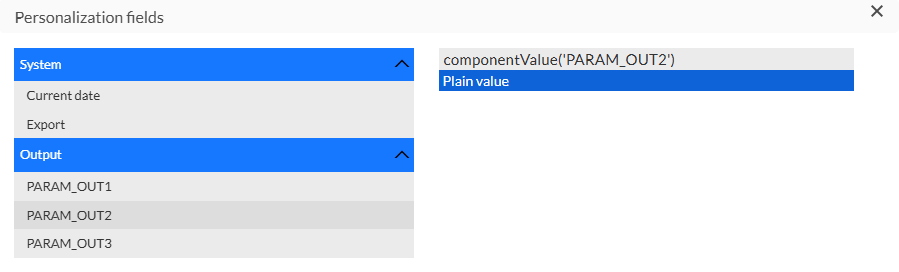
Beachten Sie, dass die Ausgabeparameter nur ausgewählt werden können, wenn sie in der oben ausgewählten Stored Procedure (in Datenquelle) konfiguriert sind: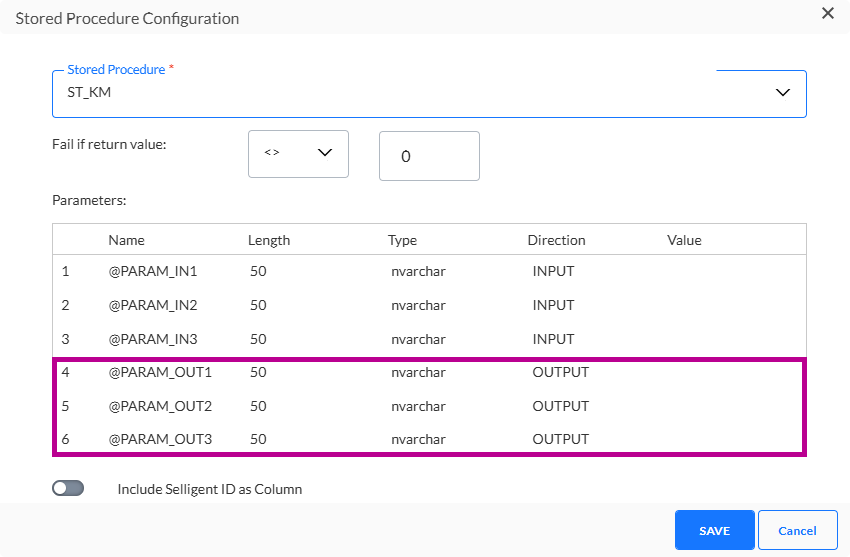
Wenn in der Stored Procedure keine Ausgabeparameter festgelegt sind, sieht der Personalisierungsdialog wie folgt aus: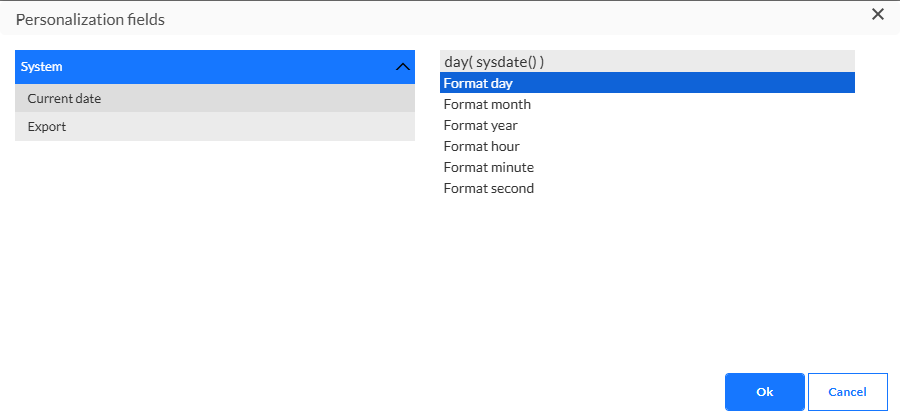
2. Legen Sie als Nächstes die Optionen für den Dateityp fest. Klicken Sie auf das Stiftsymbol, um auf den folgenden Dialog zuzugreifen:
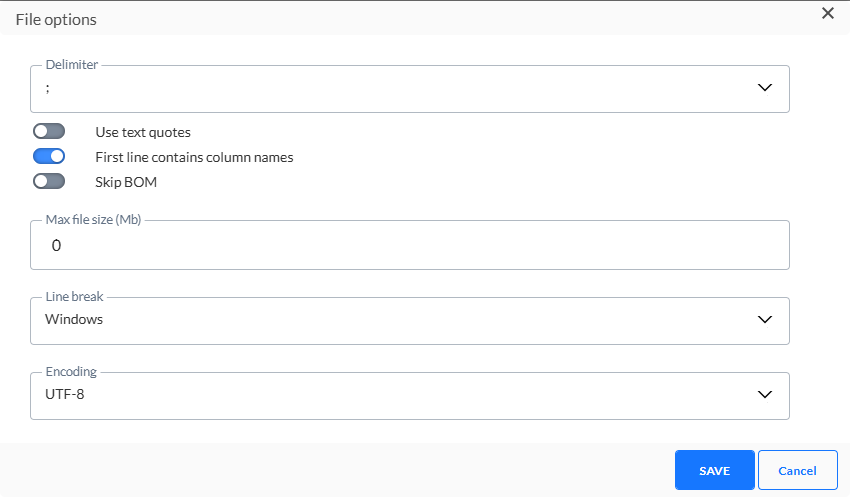
- Das Dateitrennzeichen kann auf Doppelpunkt, Strichpunkt, Tabulator oder Pipe-Zeichen eingestellt werden. Standardmässig ist das Trennzeichen auf ; eingestellt.
- Ein Einschliessen des Texts mit doppelten Anführungszeichen ist möglich. Schalten Sie die Option ein, wenn Sie dies möchten.
- Sie können ausserdem die erste Zeile als diejenige festlegen, die die Spaltennamen enthält. Diese Option ist standardmässig auswählt.
- Die Option "BOM überspringen" ermöglicht es Ihnen die Byte-Reihenfolge-Markierung am Anfang eines Textstreams zu berücksichtigen.
- Legen Sie die maximale Dateigrösse, in Megabyte ausgedrückt, fest.
- Stellen Sie den Zeilenumbruch entweder auf Windows oder Unix ein. Windows verwendet Carriage Return und Line Feed ("\r\n") als Zeilenende, während Unix nur Line Feed ("\n") verwendet.
- Legen Sie die Art der Codierung fest, die auf die Datei angewandt werden soll. Klicken Sie auf die Dropdown-Liste, um auf eine umfassende Liste von Codiermechanismen zuzugreifen.
3. Wenn Sie mit diesen Optionen fertig sind, klicken Sie auf das Symbol Speichern, um sie zu validieren. Jetzt wird eine Zusammenfassung der ausgewählten Optionen angezeigt und alle Optionen werden ausgeblendet.
Hinweis:
Es werden nur Dateien im CSV-Format unterstützt.
Es wird empfohlen (ist aber nicht zwingend erforderlich), den Dateinamen mit der Endung .csv anzugeben.
Beispiel:
- mit der Erweiterung .csv :
- ohne Erweiterung :
Erweitert
Der folgende Satz an Optionen kann jetzt konfiguriert werden:
- Sequenznummer einbeziehen — Gibt an, ob eine Reihenfolgenummer zum Dateinamen hinzugefügt werden muss. Dies ermöglicht das Inkrementieren der erzeugten Dateinamen und wird im Allgemeinen verwendet, um die Dateien zu identifizieren, die durch aufeinanderfolgende Exporte erzeugt wurden.
- Vorhandene Zieldatei überschreiben und Ordnerspeicherort erstellen, falls nicht vorhanden — Wenn die ausgewählte Zieldatei bereits vorhanden ist, wird sie überschrieben, falls die Option ausgewählt ist. Wenn die Option nicht ausgewählt ist, schlägt der Export bei Ausführung fehl.
- Wenn keine Daten für den Export zur Verfügung stehen: :
- Export überspringen — Falls die ausgewählte Liste, das Segment und der Filter keine Datensätze zurückgeben, wird der Export nicht ausgeführt.
- Export als fehlgeschlagen markieren — Falls die ausgewählte Liste, das Segment und der Filter keine Datensätze zurückgeben, wird der Export als fehlgeschlagen betrachtet.
- Export fortsetzen — Der Export wird fortgesetzt, auch wenn keine Daten vorhanden sind.
5. Als Nächstes können Sie angeben, ob eine Trigger-Datei verwendet wird. Wenn die Option markiert ist, wird ein zusätzlicher Schritt zum Assistenten für die Erstellung der Exportaufgabe hinzugefügt. Im folgenden Abschnitt erfahren Sie mehr über diese Option.
6. Und zuletzt können Verschlüsselung und Zippen aktiviert werden. Wenn diese Option markiert ist, enthält der Assistent einen zusätzlichen Schritt.
Optional — Trigger-Datei definieren
Eine Trigger-Datei wird aus zwei Gründen verwendet:
- Eine Trigger-Datei kann den Status eines bestimmten Uploads angeben. Wenn zum Beispiel die Exporte sofort ausgewählt werden, nachdem sie an ihrem Ziel ankommen, ist es für den Empfangsvorgang manchmal nicht möglich, zu wissen, ob die Datei bereits vollständig hochgeladen wurde. In anderen Worten, der Empfangsvorgang kann versuchen, auf Daten zuzugreifen, die zurzeit übertragen werden. Eine Trigger-Datei, die direkt nach dem Exportieren der Datendatei erstellt wird, kann vom Empfangsvorgang als Hinweis auf ein vollständiges/erfolgreiches Hochladen verwendet werden.
- Trigger-Dateien können ausserdem verwendet werden, um Metadaten über Ihren Export zu speichern, wie zum Beispiel die Anzahl der Datensätze oder die Zeit, zu der der Export erstellt wurde. In der Theorie kann die Datei alles enthalten, was Sie mit dem gespeicherten Verfahren (Prozessor) "abfragen" können, das die Inhalte der Trigger-Datei ausfüllt.
Hinweis: Für diese Trigger-Datei kann jede Erweiterung verwendet werden (z.B. dateiname.tgr).
Gehen Sie wie folgt vor, um eine Trigger-Datei zu definieren:
Datenquelle
1. Aktivieren Sie die Verwendung einer Trigger-Datei, wodurch ein Schritt Trigger-Datei hinzugefügt wird.
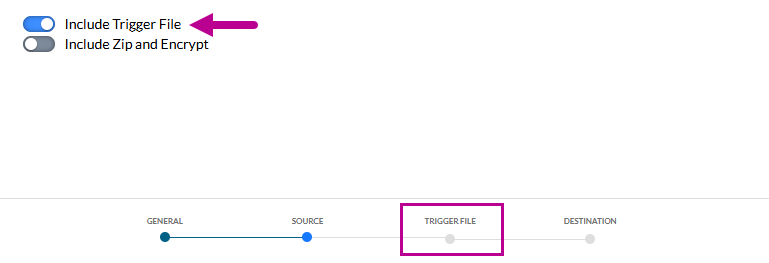
2. Wechseln Sie zum Schritt Trigger-Datei und aktivieren Sie das Kontrollkästchen Datenquelle.
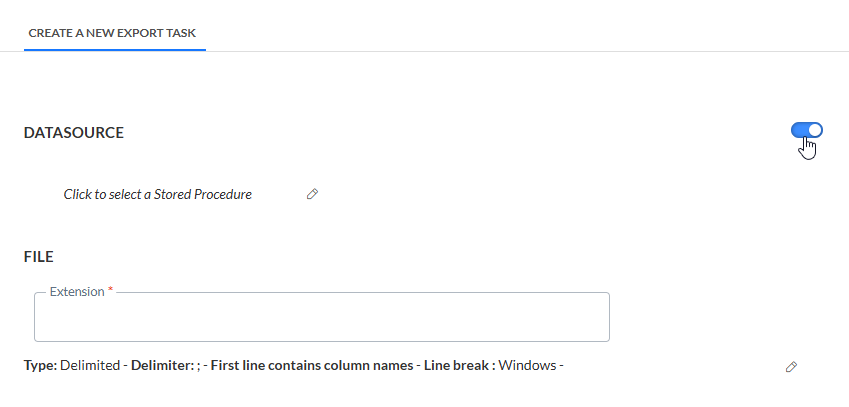
3. Klicken Sie auf das Stiftsymbol Stored Procedure, um das folgende Dialogfeld aufzurufen:
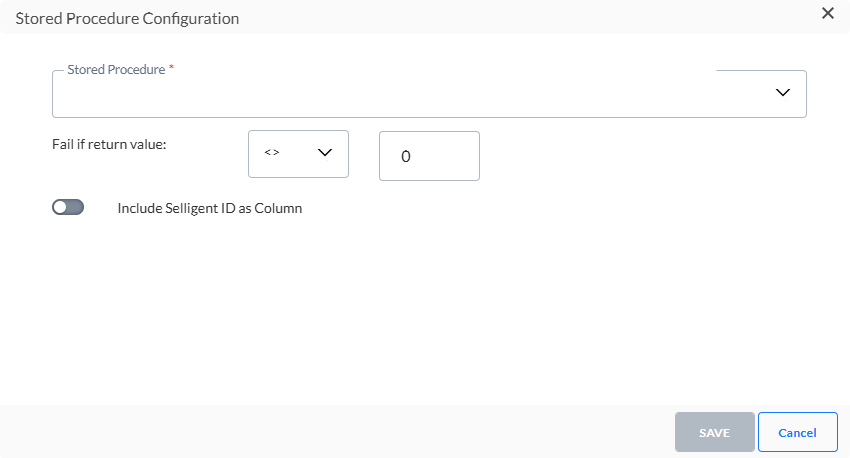
4. Wählen Sie aus der Dropdown-Liste das gespeicherte Verfahren aus, das zum Ausfüllen der Trigger-Datei verwendet wurde. Dies muss nicht dasselbe gespeicherte Verfahren wie für die Exportdatei sein.
5. Legen Sie als Nächstes das Fail-Constraint fest. Verwenden Sie den zurückgegebenen Wert des gespeicherten Verfahrens, um zu definieren, ob es fehlgeschlagen ist oder nicht.
-
Wenn im Entwurf des Stored Procedure kein expliziter Rückgabewert definiert ist, wird im Erfolgsfall der Wert 0 standardmäßig zurückgegeben. Andere Werte implizieren einen Fehler.
In diesem Fall stellen Sie das Fail-Constraint wie folgt ein: Fehler, wenn Rückgabewert <> 0.
-
Wenn der Entwurf für das Stored Procedure ein oder mehrere benutzerdefinierte Rückgabewerte enthält, hängen die Werte, die bei Erfolg oder Fehler zurückgegeben werden, von diesem Entwurf ab.
In diesem Fall entscheiden Sie, was Sie als Fail-Constraint betrachten.Beispiel 1:
Das Stored Procedure, das verwendet wird, definiert, dass der Wert 10 nach Ausführung bestimmter SQL-Anweisungen zurückgegeben wird und der Wert 12 nach Ausführung eines anderen Satzes von SQL-Anweisungen zurückgegeben wird.
Sie betrachten den Teil, der den Rückgabewert als 12 definiert, als einzigen erfolgreichen Teil. In anderen Fällen sollte er als Fehler betrachtet werden.
In diesem Fall stellen Sie das Fail-Constraint wie folgt ein: Fehler, wenn Rückgabewert <> 12.Beispiel 2:
Das verwendete Stored Procedure definiert die Rückgabewerte 1, 10, 50, 51, 52, 53, 54, 55, 56, 60.
Sie betrachten die Rückgabewerte 1, 10 und 50 als „erfolgreiche“ Werte. Die anderen geben an, dass etwas falsch ist, und werden daher als Fehler betrachtet.
In diesem Fall können Sie das Fail-Constraint wie folgt einstellen: Fehler, wenn Rückgabewert >= 51.
6. Sie können die Selligent-ID als Spalte in der Trigger-Datei einbeziehen. Diese ID ist eine Kombination des Zielgruppenlisten-ID und Kontakt-ID. Wenn Sie dies möchten, schalten Sie die Option ein und geben Sie einen Namen für die Spalte an.
7. Speichern Sie die änderungen und füllen Sie die Eigenschaften im Abschnitt "Datei" aus.
Datei
1. Geben Sie eine Erweiterung für die Trigger-Datei an. Dies kann jede gewünschte Erweiterung sein, wie z.B. *.xp, *.trg oder irgendetwas anderes.
2. Klicken Sie als Nächstes auf das Stiftsymbol neben dem Feld Typ, um zu den Dateieigenschaften zu gelangen.
- Trennzeichen — Das Dateitrennzeichen kann auf Doppelpunkt, Strichpunkt, Tabulator oder Pipe-Zeichen eingestellt werden.
- Text-Anführungszeichen verwenden — Das Einschliessen des Texts mit doppelten Anführungszeichen ist möglich. Schalten Sie die Option ein, wenn Sie dies möchten.
- Erste Zeile enthält — Sie können ausserdem die erste Zeile als diejenige festlegen, die die Spaltennamen enthält.
- Zeilenumbruch — Stellen Sie den Zeilenumbruch entweder auf Windows oder Unix ein. Windows verwendet Carriage Return und Line Feed ("\r\n") als Zeilenende, während Unix nur Line Feed ("\n") verwendet.
3. Klicken Sie, wenn Sie fertig sind, auf Speichern.
Optional — Verschlüsseln und zippen
Dieser Schritt ermöglicht Ihnen das Verschlüsseln und Zippen der Exportdatei und ausserdem das Auswählen, was zuerst erfolgen sollte, wenn beide Optionen aktiviert sind.
Zippen — Diese Option zippt die Exportdatei, bevor sie zum Ziel gesendet wird. Wenn die Option ausgewählt ist, kann der Benutzer sich für einen benutzerdefinierten Namen oder für einen Namen entscheiden, der automatisch aus der Quelle erstellt wird.
Verschlüsseln — Wählen Sie diese Option aus, um die erzeugte Exportdatei zu verschlüsseln. Wenn die Option aktiviert ist, muss die E-Mail-Adresse des Empfängers ausgefüllt werden. Diese Adresse wird verwendet, um den öffentlichen Schlüssel zu senden, der für die Verschlüsselung verwendet wird.
Technischer Hinweis:
Um eine verschlüsselte Datei von der Selligent by Zeta-Plattform an einen externen Speicherort zu senden..
• Senden Sie den öffentlichen Schlüssel Ihres PGP-Schlüssels an Zeta. Sie können diesen Schlüssel an ein Zeta Support-Ticket anhängen. Ein Support-Mitarbeiter sorgt dafür, dass dieser Schlüssel in der Plattform richtig konfiguriert wird.
--- Wenn Sie noch keinen eigenen PGP-Schlüssel erstellt haben, lesen Sie bitte weiter unten in diesem Dokument den Abschnitt „Wie man einen PGP-Schlüssel erstellt“.
--- Senden Sie niemals den privaten Schlüssel dieses PGP-Schlüssels an Dritte! Zeta wird Sie auch niemals auffordern, diesen Teil des Schlüssels an einen seiner Mitarbeiter zu senden.
• Konfigurieren Sie eine Datenexportaufgabe, um diese Datei an einen externen Speicherort zu exportieren..
--- Aktivieren Sie in den Quelloptionen dieser Aufgabe die Option „Zippen und Verschlüsseln einbeziehen“
--- Füllen Sie im nächsten Schritt das Feld „Empfänger“ aus, das mit Ihrem PGP-Schlüssel verknüpft ist, um die Datei zu verschlüsseln.
Wie man einen PGP-Schlüssel erstellt
Laden Sie Ihr bevorzugtes Management-Tool für PGP-Schlüssel hier herunter: https://gnupg.org/download/index.html. Legen Sie die heruntergeladenen Binärdateien im Ordner C:\PGP ab und befolgen Sie die folgenden Beispielschritte.
• Öffnen Sie ein Eingabeaufforderungsfenster
• Erzeugen Sie einen Signierschlüssel mit dem Befehl: gpg.exe --homedir "C:\PGP\PGPDB" --gen-key
--- Wählen Sie eine Option: (5) RSA (nur signieren)
--- Schlüsselgröße: 4096
--- Ablauf des Schlüssels: 0 (Schlüssel läuft nicht ab)
--- Ist dies korrekt? Y
--- Benutzerkennung:
-------- Echter Name:: <YourCompanyName>
-------- E-Mail-Adresse (Empfänger): <UniqueAddressPerPgpKey>
-------- Kommentar: 4096bit PHP-Schlüssel für <YourCompanyName>
-------- Bestätigen Sie mit: o (Okay)
---- Geben Sie eine sichere Passphrase ein: <YourSecurePassphrase>
• Notieren Sie sich die ID des erstellten Signierschlüssels. Wir brauchen sie im nächsten Schritt. Rufen Sie diese ID mit folgendem Befehl ab: gpg.exe --homedir "C:\PGP\PGPDB" -list-keys
• Erzeugen Sie einen Verschlüsselungsschlüssel mit folgendem Befehl: gpg.exe --homedir "C:\PGP\PGPDB" --edit-key <ID>
--- Geben Sie die Passphrase ein: <YourSecurePassphrase>
--- Befehl> addkey
--- Wählen Sie eine Option: (6) RSA (nur Verschlüsselung)
--- Schlüsselgröße: 4096
--- Ablauf des Schlüssels: 0 (Schlüssel läuft nicht ab)
--- Ist dies korrekt? Y
--- Wirklich erstellen? Y
--- Befehl> save
• Exportieren Sie den öffentlichen Schlüssel des PGP-Schlüssels, der aus dem PGP-Schlüsselbund generiert wurde, mit dem Befehl: gpg.exe --homedir "C:\PGP\PGPDB" -- exportieren Sie einen <UniqueAddressPerPgpKey>| Out-File -FilePath "C:\PGP\MyPublicKey.asc"</UniqueAddressPerPgpKey>
Ziel
Im letzten Schritt wird das Ziel der Exportdatei definiert. Sie haben die Auswahl aus den folgenden Optionen: Repository, FTPS, FTPS implizit, SFTP, Azure Blob-Speicher, Amazon S3-Speicher, Google Cloud-Speicher oder vordefiniert. Je nach Medium sind verschiedenen Einstellungen definiert:
SFTP, FTPS, FTPS implizit — Der Name des Servers sowie der Benutzer und das Passwort zum Verbinden mit dem Server sind erforderlich. Der Benutzer kann einen spezifischen Unterordner angeben, in dem die Datei gespeichert werden soll. Standardmässig ist bereits ein Unterordner ausgewählt.
Hinweis: Ausdrücke für UNTERVERZEICHNISSE werden jetzt genauso unterstützt wie für die Definition von Dateinamen in einer Exportaufgabe
Authentifizierung mit privatem Schlüssel
Bei SFTP kann neben der Verwendung eines Passworts zur Authentifizierung bei der Verbindung mit dem Server auch ein privater Schlüssel verwendet werden:
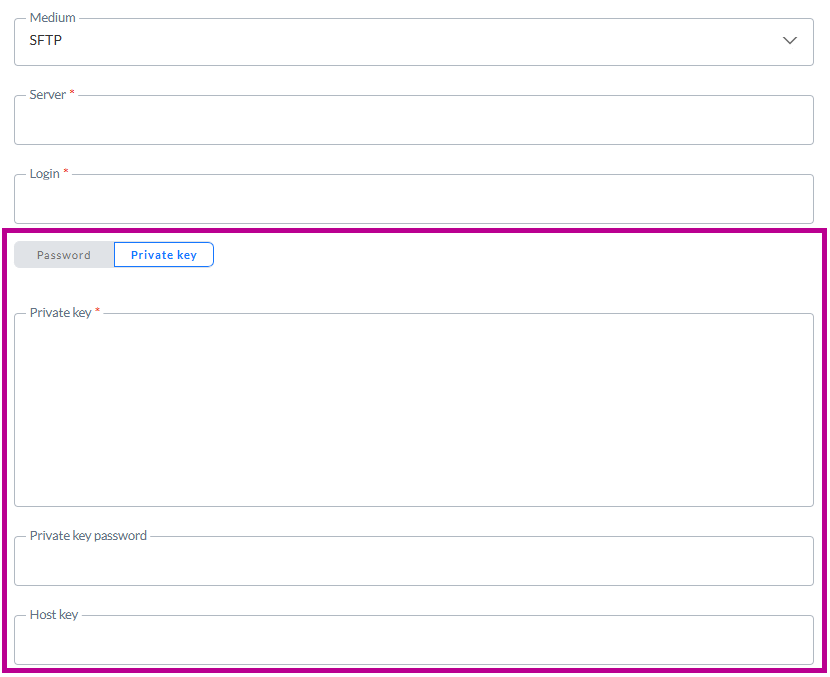
Mit einem Umschalter können Sie entweder Passwort oder Privater Schlüssel auswählen. Wenn Privater Schlüssel ausgewählt ist, können Sie die Daten des privaten Schlüssels in das Feld Privater Schlüssel eingeben (oder mit Copy und Paste einfügen).
Wichtig: Wir unterstützen nur PuTTY private Schlüssel für SFTP-Exporte. Achten Sie also bitte auf das richtige Format. Das PuTTY-Benutzerhandbuch finden Sie hier.
Wenn für den privaten Schlüssel ein Passwort erforderlich ist (bei einigen Servern ist dies der Fall), können Sie das Passwort in das Feld Passwort für den privaten Schlüssel eingeben. Dies ist ein optionales Feld.
HinweisDie Daten aus beiden Feldern (privater Schlüssel und Passwort für den privaten Schlüssel) werden verschlüsselt in der Datenbank gespeichert und nur bei der Übertragung der Dateien verwendet
Der Host-Schlüssel ist ein optionales Feld, das als zusätzlicher Überprüfungsschritt verwendet werden kann, um sicherzustellen, dass Sie sich mit dem richtigen Server verbinden.
HinweisBeim Speichern der/des [Importaufgabe/Datenimports/Exportaufgabe/Datenexports/Mediums]:
– Der Inhalt des Feldes für den privaten Schlüssel wird geleert (aus Sicherheitsgründen)
– Das Label des Feldes für den privaten Schlüssel wird auf Einen neuen privaten Schlüssel angeben, um den vorhandenen privaten Schlüssel zu aktualisieren aktualisiert
– Der Inhalt des Feldes für das Passwort des privaten Schlüssels wird geleert (aus Sicherheitsgründen)
– Das Label des Feldes für das Passwort des privaten Schlüssels wird auf Ein neues Passwort für den privaten Schlüssel angeben, um den vorhandenen privaten Schlüssel zu aktualisieren aktualisiert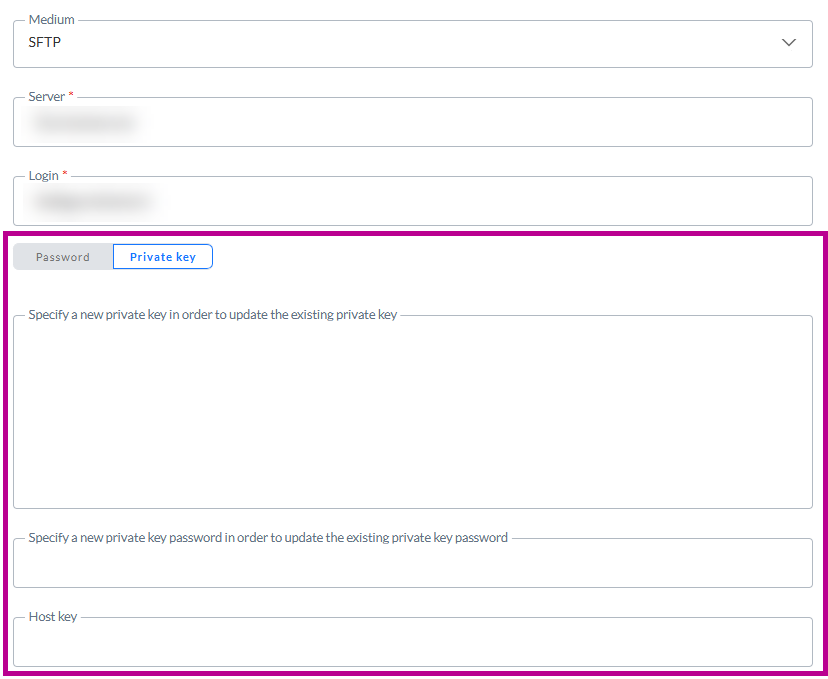
Repository — Das Repository ist das lokale Dateisystem des Job-Agenten. Das Dateisystem enthält bereits den Ordner Campaign-Daten, in dem ein Unterordner ausgewählt werden kann. Klicken Sie auf das Dropdown-Menü, um den Unterordner für das Speichern der Datei auszuwählen.
Azure Blob-Speicher – Geben Sie die Verbindungszeichenfolge (Sie können die Sichtbarkeit der Zeichenfolge durch Klicken auf das Augensymbol ein- und ausschalten) und den Container und einen optionalen Unterordner an. (*)
Amazon S3-Speicher – Geben Sie die ID des Zugriffsschlüssels und den geheimen Zugriffsschlüssel (Sie können die Sichtbarkeit beider Zeichenfolgen durch Klicken auf das Augensymbol ein- und ausschalten), den Bucket-Namen, den Code des Regionsendpunkts und einen optionalen Unterordner an. (*)
Google Cloud-Speicher – Geben Sie den Typ, die Projekt-ID, die ID des privaten Schlüssels und den privaten Schlüssel (Sie können die Sichtbarkeit beider Zeichenfolgen durch Klicken auf das Augensymbol ein- und ausschalten), die Client-E-Mail, die Client-ID, die Auth-URI, die Token-URI, die URL des Authprovider X509-Zertifikats, die URL des Client X509-Zertifikats, den Bucket-Namen und einen optionalen Unterordner an. (*)
Vordefiniert – Beim Auswählen dieser Option wird das Feld „Vordefiniertes Transportmedium“ angezeigt, in dem Sie ein Medium aus einer Liste vordefinierter Medien auswählen können. Diese Medien sind bereits in der Admin-Konfiguration konfiguriert und mit Ihrem Geschäftsbereich verknüpft. Wenn Sie eines auswählen, werden alle entsprechenden Einstellungen verwendet.
* Hinweis: Details dazu, wie Cloud-Speicherkonfigurationen eingerichtet werden, sind hier zu finden..
Hinweis: Wenn Sie nicht über die Berechtigung verfügen, ein Medium zu definieren, ist der Medium-Abschnitt beim Bearbeiten der Aufgabe schreibgeschützt, und beim Erstellen einer neuen Aufgabe kann nur ein vordefiniertes Medium ausgewählt werden.
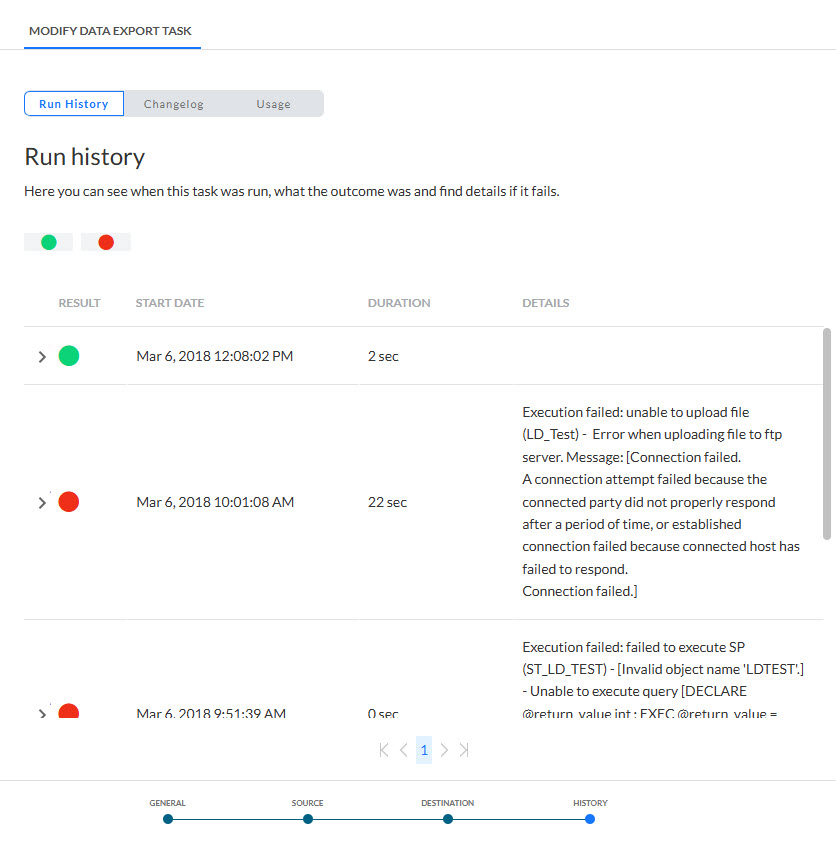
Verlauf
Der Verlauf liefert Informationen darüber,
- wann diese Aufgabe geändert (aktualisiert, gelöscht) wurde und von wem. Diese Information ist auf der Registerkarte „Änderungsprotokoll“ verfügbar.
- wann die Aufgabe ausgeführt wurde, sowie der Status dieser Ausführung. Diese Informationen sind auf der Registerkarte „Ausführungsverlauf“ verfügbar. Wenn die Aufgabe Teilaufgaben umfasst, kann der Ausführungsverlauf dieser Aufgaben ebenfalls eingesehen werden.
- wo die Aufgabe verwendet wird. Diese Informationen sind auf der Registerkarte „Nutzung“ verfügbar.
Verwenden Sie die Filtersymbole oben, um den Ausführungsverlauf zu filtern.
Wenn Sie die Eigenschaften konfiguriert haben, können Sie auswählen, ob Sie die Aufgabe speichern oder sofort speichern und aktivieren möchten.
